The situation
A former colleague of mine reached out regarding an contracting opportunity with a startup. Part of their technology solutions involve training machine learning models using data they collect from IoT devices deployed on their customers’ premises. In true startup fashion, they had initially “solved” the problem of data ingestion by installing a commercial cloud storage client on their devices and saving all their data to this folder, letting the sync client do the work. This let them get to market quickly, but was not scaling well as their data volume quickly grew.
They needed to implement a more scalable data pipeline better suited to high throughput, low latency ingestion of small files, and easier data access for analytics and machine learning application. All of this needed to be setup within their existing AWS account.
The pitch
My original pitch was to author a technical design document proposing an architecture for their data pipeline and warehousing, starting with an analysis of their business domain and data model, followed by a complete system architecture, security model, component design decisions, infrastructure, and development roadmap.
The client accepted this pitch, and I did work on the document for a while. However, it became clear to both of us early on that a fast-paced startup like this one couldn’t afford a waterfall approach. So, I proposed a pivot to incrementally developing the components of the data pipeline, in order of urgency. Their top priority was the data ingestion component, since cleaning and processing could be done at any time once the data was stored.
Project highlights
While I had experience with python, data engineering was relatively new to me aside from the pipeline I build for Every Voice. I had to self-educate on the job, especially with regards to concurrecy and parallel processing in Python.
System architecture
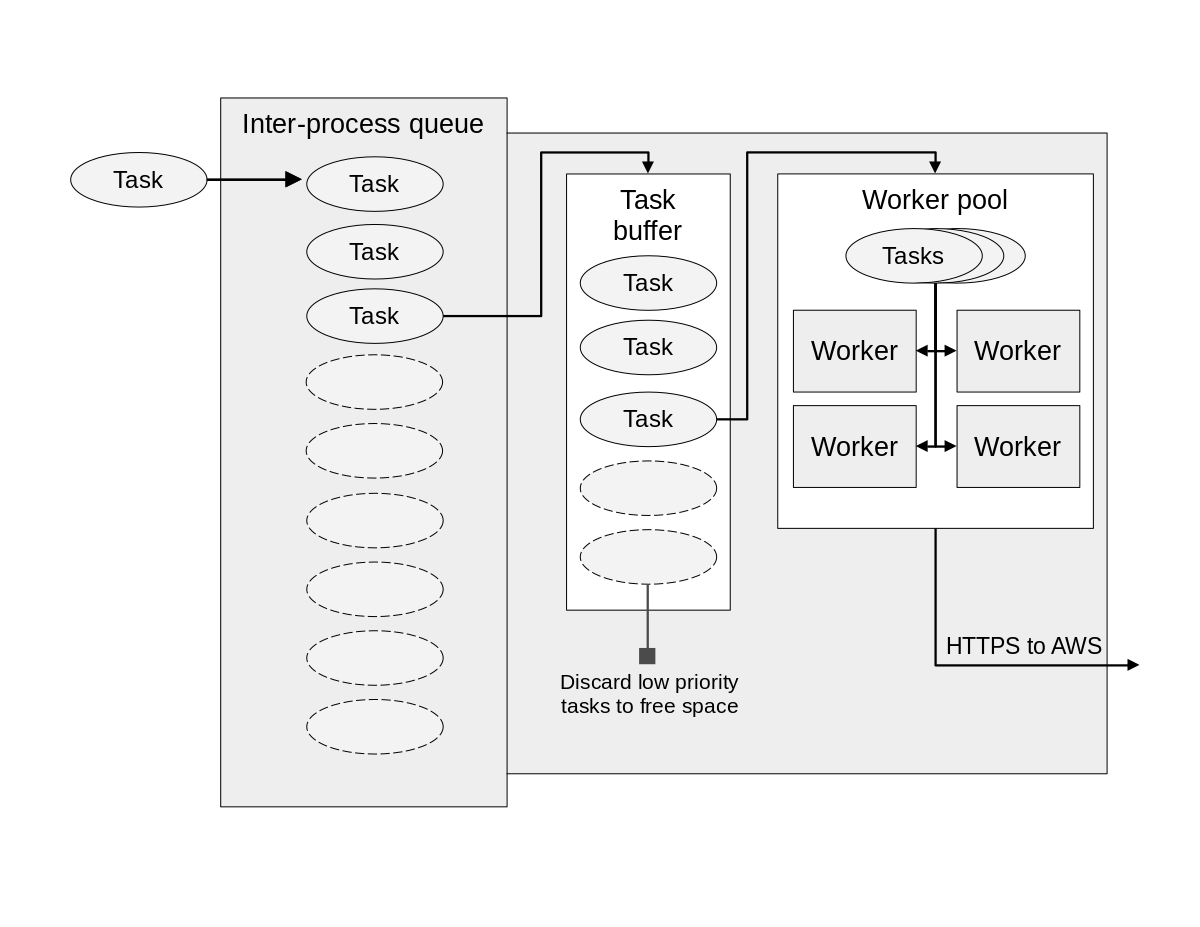
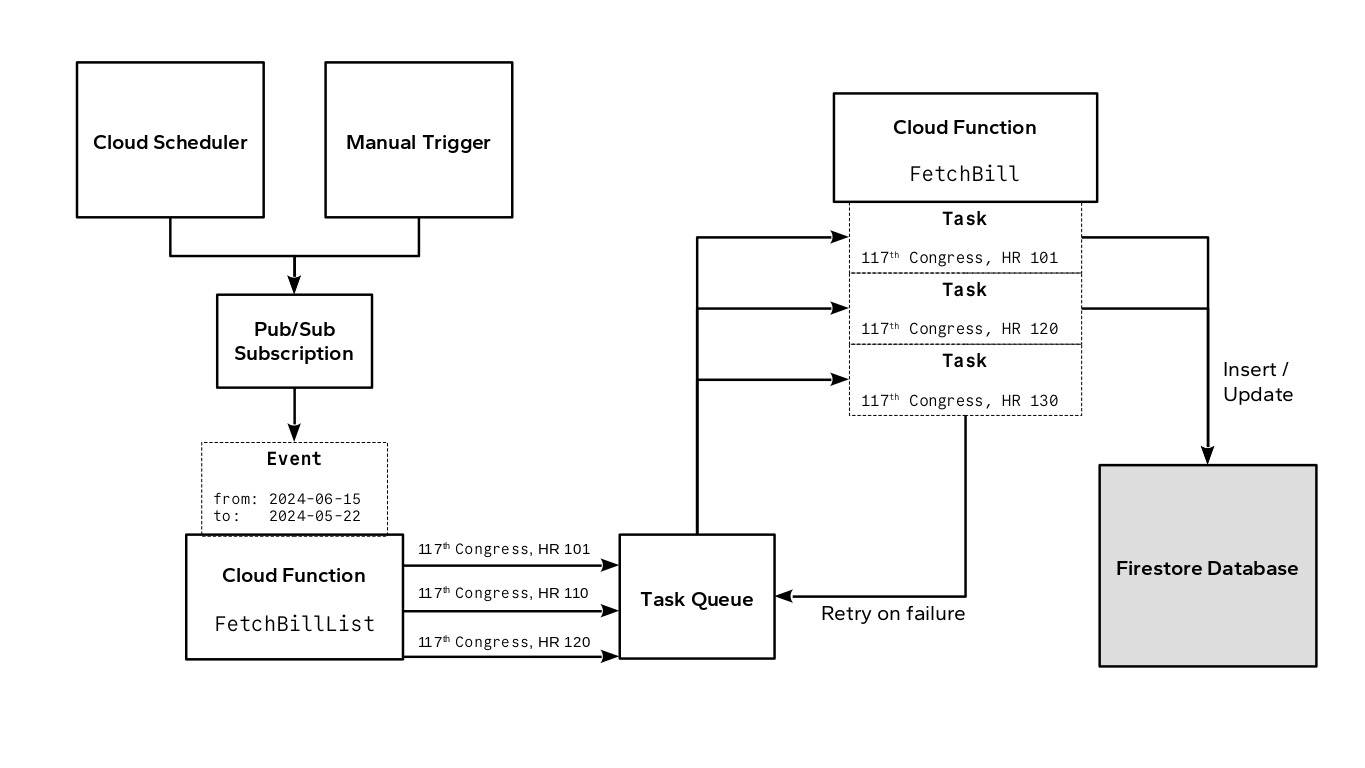
It took several iterations to land on an appropriate architecture for the uploader component, due to challenges meeting the operational requirements and constraints. In particular, the upload service:
- Must not block the program’s main application loop, since this is the IoT device’s primary job.
- Should not consume unnecessary device CPU or memory resources, as the main application loop needs as much as possible.
- Should be fault-tolerant and lossless with respect to device shutdowns and unstable network connections.
- Should require minimal authorizations to access AWS resources from the client’s account, to prevent abuse if the device is compromised.
To satisfy the first constraint, the uploader service runs in a separate Python process, using the multiprocessing library. The main application passes file upload tasks to the uploader service via an inter-process queue. The uploader process then pulls tasks from the queue to execute them.
In designing and implementing this system, I adhered to the time-honored UNIX philosophy of “Do one thing well.” Each component has a single primary responsibility, which simplified the test-driven development approach that guided my implementation.
The core of the uploader service is the upload loop which executes three steps on repeat:
- Pull a task from the queue into the task buffer.
- Filter out low-priority tasks from the buffer.
- Submit a task to the worker pool.
It will help to go through these one at a time.
Pull a task from the queue
During the first step of each cycle of the process loop, the uploader pulls a task from the queue and adds it to the task buffer. Tasks leave the queue in the order they are added (First-in, First-out). If the task buffer is empty, the program will wait at this step (also known as “blocking”) until there’s a task to retreive, since there’s no other work to be done.
The main application writes files to the local device before submitting an upload task to the queue. This way, if a task fails to upload due to an unexpected shutdown or other issue, the file can be discovered and uploaded the next time the device boots.
The task buffer is nothing special; it’s a simple ordered list stored in uploader process memory. The buffer prevents the interprocess queue from filling up, without discarding important tasks, thanks to step two…
Filter the task buffer
If the task buffer is full, the second step of the process loop may discard some tasks to make room for more. This way, the uploader can always take a new task from the queue, which means the queue should never reach its capacity. This is important, because a full interprocess queue would prevent the main app from adding more tasks.
Every file upload task send to the uploader has a “priority” property set to one of three levels, “LOW”, “MEDIUM”, or “HIGH”. High priority tasks are never dropped, so this level is reserved for only the most critical files. Medium and low priority tasks are dropped when the task buffer fills and the interprocess queue has reached a threshold percentage of capacity. These thresholds are set in the uploader’s configuration settings.
As an example, assume the threshold for dropping low priority tasks is set to 70%. If, during step two of a cycle, the task buffer is full, and the queue is at, say, 75% of capacity, the service will discard all low priority tasks in the buffer.
Submit tasks to the worker pool
In step three of the loop, the uploader pulls a task off the task buffer (again in FIFO order) and attempts to submit it to the worker pool. This component is responsible for executing file uploads concurrently (rather than one by one). Each worker in the pool has a very straightfoward job: read the file referenced by the task from the local device, and use the AWS Python SDK boto3 to upload the file to S3.
If there is space in the pool for the task, the submission succeeds, otherwise if fails. Normally, task submission is non-blocking, so if the submission fails the uploader immediately proceeds to step one of the next loop cycle. However, if the task buffer is full, but the queue has not yet reached a threshold for the buffer to start dropping tasks, the loop will pause for one second to see if space in the pool frees up. If not, it will release and start the next cycle and potential discard tasks before retrying submission.
The worker pool leverages Python’s ThreadPoolExecutor from the concurrent.futures library. By default, a Python thread pool just accepts every task sent its way, adding it to an internal buffer whose memory footprint grows if tasks are added faster than they are removed. Since we want to keep this footprint small, the worker pool implements a bounded semaphore. A semaphore is essentially a “thread-safe” counter. We increment the counter by 1 when a task is accepted by the worker pool. Then, each time a worker thread completes a task, it decrements the counter by 1. The thread-safe property is important; without it, two workers might try to decrement the counter simultaneously, leading to undefined behavior.
Along with the task itself, the uploader attached a post-success handler to each submission. When the worker reports a successful upload, the handler then deletes the file from the local device.
Optimizing memory footprint
I’m pretty familiar with the kinds of performance metrics used to evaluate a web-based application. A data pipeline was a different story. The big challenge here was ensuring the uploader didn’t demand too much memory from the local device; otherwise, the performance of the main application would degrade.
The uploader allocates memory in three main places:
- The inter-process queue
- The task buffer
- The worker pool (including both the processes and its internal buffer)
We can constraint the maximum amount of memory allocated to these components by adjusting a few variables: the capacity of the queue, the capacity of the task buffer, the number of workers in the pool, and the worker pool’s internal buffer.
While I won’t share exact numbers here, I can summarize my approach.
- First, I estimated the average size, in bytes, of a single task held in memory. Keep in mind that a task moving through the uploader only needs to hold the full path to a file, not the file’s contents. So, each task in memory is likely only a few tens of bytes.
- Next, I assumed that the memory footprint of the worker threads would be approximately equal to one task, since the code to execute a worker was fairly small. That meant I could focus primarily on the queue and buffer.
- Through some experimental trial and error, I landed on an appropriate size for the task buffer large enough to preclude frequent discarding of tasks.
- All the remaining memory alloted to the uploader could be assigned to the queue.
- The worker pool’s internal buffer was set to some small multiple of the number of workers, such that each worker would have a few tasks waiting for it when it finished one, but a negligible memory footprint.
Securing and provisioning infrastructure
I’ve been talking a lot about the client side of the data pipeline, but what about the back-end? AWS S3 handles accepting the upload and storing it, but there’s still the problem of access control. Since these devices are fully automated, it would be impracticale for developers to constantly remote connect to each one and re-enter a username and password just to retrieve new credentials when the previous ones expired. Plus, these devices are out in the world with customers who can physically access them. As always, proper security is essential.
To avoid potential breaches or exploitations, I followed the principle of least privilege, which demands that any authorized agent be granted the absolute bare minimum access needed to do the job properly. For the uploader service, this involved short-lived credentials to a write-only access point. Here’s the full breakdown. It may be difficult to follow if you’re not familiar with AWS permissions, but I’ll do my best to keep things simple.
- Each device receives a set of long-term AWS credentials (access key + secret key) loaded into a file on the device. These credentials are associated with an AWS user.
- The AWS user is granted just one permanent permission: the ability to “assume” a role named “Uploader”. When a user assumes a role, they are granted all the permissions of that role for a short period of time (typically one hour). The “Uploader” role’s policy requires the device to provide a customer id, which must match the customer id assigned to AWS user whose credentials are being used. This ensures that the device cannot “spoof” another customer.
- The target for file uploads is an S3 bucket. This bucket cannot be accessed directly; instead, an “access point” is created that allows for file writing, but not reading. This provides a layer of protection for the bucket, as devices do not need to store the buckets true name in the code or configuration. Malicious actors probing the access point will never be able to read anything from it.
- The “Uploader” role has permissions to write to the S3 bucket via the write-only access point. This permission is restricted by a policy that only allows files to be written if their label is prefixed with the customer id given when the user assumed the role. E.g. if the device assumed the “Uploader” role with customer id “7000”, it could write files to the bucket, but only if the files are prefixed with
7000/. This ensures the device respects the multi-tenant nature of the bucket and does not corrupt files for other clients.
Area of improvement: Keeping project scope small
My original proposal to this client was a massive technical design document. Then, when we pivoted to incremental development, I scoped out not just the uploader service but an entire data lake and warehouse as well. In hindsight, that was way too much in a short span of a few months. Fortunately, this client saw the value of the work that I was able to accomplish and embraced my Fractional Plan instead. I am now working with them part-time on whatever they need, when they need it.
In future engagements, I’m going to be more intentional about keeping project proposals small, breaking them into value-adding milestones as needed.
Final takeaway
I learned an immeasurable amount while working on the uploader. Most importantly, the solution I implemented is still in use, uploading gigabytes of data every day as of this writing. I’m eager to find more opportunities to delve into the data engineering space. If you’re searching for a versatile developer to help your team accelerate their delivery, please reach out!
]]>